

Table of Contents
- Une brève histoire de la piraterie littéraire
- Comment ça marche, ce partage illicite ?
- Quand Meta joue les pirates de haute mer
- Pourquoi Meta s’est-elle transformée en pirate ?
- Le grand bluff : comment Meta a tenté de dissimuler tout ça
- Les conséquences (morales, légales, et tout le bazar)
- Vers une armada de livres écrits par des IA ?
- Comment sortir de cette zone grise ?
- La grande question : pirates ou sauveurs du savoir ?
- Et vous, qu’en pensez-vous ?
Dans l’imaginaire collectif, le terme « piraterie » n'a aucune relation avec "meta" mais renvoie plutôt à ces téléchargeurs clandestins de blockbusters hollywoodiens ou de jeux vidéo ultra-populaires. Mais saviez-vous qu’il existe aussi des pirates… de livres ? Oui, ces « flibustiers littéraires » qui arpentent le web pour dénicher romans, manuels scolaires, encyclopédies et autres trésors du savoir. Des plateformes telles que Z-Library ou Library Genesis (LibGen) regorgent d’ouvrages à portée de clic, pour le meilleur et pour le pire.
Jusque-là, on aurait pu croire que seuls quelques étudiants fauchés ou des passionnés de lecture un peu rebelles s’aventuraient sur ces sites. Et puis un jour, grosse surprise : Meta (ex-Facebook) serait elle-même devenue l’une des plus grandes « pirates de livres » de la planète. Oui, vous avez bien lu. De l’entreprise de Mark Zuckerberg, on attendait peut-être un nouveau réseau social ou un casque de réalité virtuelle, pas qu’elle se mette en quête de millions de bouquins illégalement ! Alors, accrochez vos ceintures, armez-vous de votre meilleur cache-œil, et plongeons ensemble dans cette histoire rocambolesque.
Une brève histoire de la piraterie littéraire
Avant de jeter un coup d’œil aux pratiques de Meta, revenons rapidement sur la piraterie de livres en général. On pense souvent au P2P (pair-à-pair) pour télécharger des films, des séries ou de la musique. Pourtant, des communautés se sont aussi formées pour partager des PDF de romans, d’articles scientifiques et de manuels. L’idée de départ ? Rendre le savoir accessible à tous, surtout quand certains ouvrages académiques se vendent à des prix exorbitants.
Des sites comme LibGen ou Z-Library répertorient ainsi des centaines de milliers, voire des millions, de titres, allant de l’essai philosophique obscur au roman à succès. Tout ça est évidemment illégal au regard du droit d’auteur, mais ces plateformes demeurent une aubaine pour les étudiants désargentés et les curieux insatiables. En gros : même si c’est interdit, c’est drôlement tentant de pouvoir télécharger n’importe quel bouquin en quelques secondes.
Comment ça marche, ce partage illicite ?
Le mécanisme est similaire à celui des autres formes de piraterie en ligne : BitTorrent. On se connecte à un « torrent » qui contient le livre que l’on souhaite, et on télécharge le fichier en partageant des bouts de ce dernier avec d’autres utilisateurs. Pour que ce système tourne correctement, il faut rester en mode seed (envoyer les morceaux déjà téléchargés) un certain temps, afin de maintenir un « essaim » (ou swarm) solide.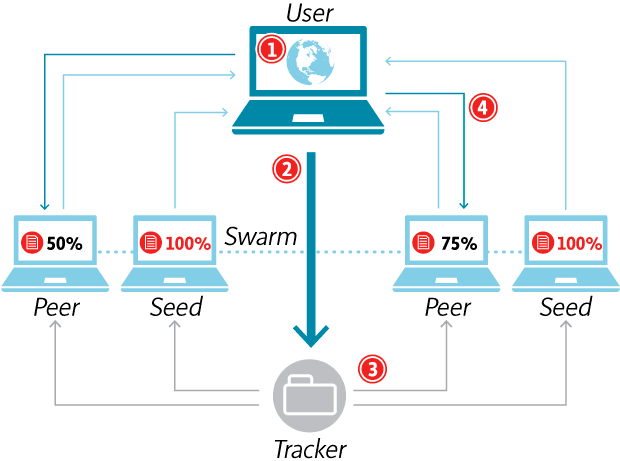
Bien sûr, comme pour les films et les séries, des éditeurs et leurs avocats veillent au grain. Certains d’entre eux se connectent incognito aux torrents et collectent les adresses IP des téléchargeurs. Ils peuvent alors contacter les fournisseurs d’accès à Internet (FAI) pour identifier les « pirates » et leur envoyer des courriers menaçants, histoire de leur faire passer l’envie de partager le dernier best-seller en date. Vous avez peut-être déjà entendu parler de ces fameuses lettres de mise en demeure…
Quand Meta joue les pirates de haute mer
Récemment, la nouvelle est tombée comme un pavé dans la mare (ou un livre dans la bibliothèque, au choix) : Meta aurait téléchargé plus de 81,7 téraoctets de livres, juste au printemps dernier, sur différents shadow libraries (Z-Library, LibGen, Anna’s Archive, etc.). Et ce n’est pas tout : avant ça, l’entreprise aurait déjà pompé 80 téraoctets d’articles scientifiques. En tout, on frôle donc les 160 téraoctets de contenus piratés – de quoi remplir un nombre colossal de liseuses et de bibliothèques virtuelles.
Pour donner une idée, 80 téraoctets de textes reviennent à plus d’un milliard de pages scannées. Imaginez un instant la pile de livres correspondante dans votre salon… En clair, Meta ne s’est pas contentée de « voler un livre » : elle a carrément embarqué tout le rayon littéraire du supermarché, le carton de la librairie d’en face, et peut-être même la réserve de la bibliothèque municipale !
Pourquoi Meta s’est-elle transformée en pirate ?
La réponse est plus simple qu’il n’y paraît : l’IA. Les intelligences artificielles actuelles, comme les modèles de langage (ChatGPT, LLaMA, etc.), ont besoin de faramineuses quantités de texte pour s’entraîner à comprendre et générer du langage. Plus on leur donne de livres, plus elles deviennent performantes.
Or, se procurer légalement des millions de livres, surtout des manuels et des articles scientifiques, c’est un parcours du combattant. Les tarifs sont élevés, les licences complexes, et même une entreprise comme Meta peut hésiter à investir des centaines de millions de dollars juste pour enrichir sa base de données. La solution la plus pratique (et la plus discutable légalement) : se tourner vers les torrents. Ni vu, ni connu… du moins, en théorie.
Le grand bluff : comment Meta a tenté de dissimuler tout ça
Selon des documents judiciaires, Meta aurait pris soin de ne pas utiliser ses adresses IP officielles pour télécharger ces livres, histoire de ne pas éveiller les soupçons. Imaginez la scène : un pirate random dans la swarm tombe sur une IP qui renvoie directement à « facebook.com »… effet garanti ! Il aurait immédiatement tweeté un truc du genre : « Holy smokes, Facebook vient de télécharger tout le rayon romance de la bibliothèque pirate ! »
En interne, des employés se sont plaints : « Ça ne semble pas très clean de lancer un torrent depuis un ordi de boulot… ». Malgré ce malaise, la pratique a continué. Cerise sur le gâteau : le grand patron, Mark Zuckerberg, a juré qu’il n’était pas au courant, mais les discussions internes le contredisent. Autrement dit, il était probablement dans la boucle au moment où Meta s’est dit : « Télécharger 160 téraoctets de bouquins illégalement ? Bah, pourquoi pas… ».
Les conséquences (morales, légales, et tout le bazar)
On pourrait se dire : « Bon, c’est juste des livres. Est-ce vraiment si grave ? ». En réalité, oui. D’abord, cette pratique porte un coup à la propriété intellectuelle. Les auteurs, surtout les moins connus, dépendent de leurs droits d’auteur pour vivre. Quand on pirate un livre, on les prive potentiellement de revenus. Quand c’est Meta qui pirate des milliers de livres, l’impact est encore plus colossal.
Ensuite, il y a l’enjeu de l’utilisation qui est faite de ces textes. Meta ne s’en sert pas pour distraire ses employés entre deux pauses-café, mais pour entraîner ses IA et, in fine, gagner de l’argent. On peut comprendre la frustration des éditeurs : « Attendez, on vend ces bouquins, et Meta les récupère gratis pour développer une IA qui pourrait, un jour, remplacer bon nombre de métiers de la création ? C’est un peu fort, non ? ».
Enfin, il y a une dimension quasi philosophique : qu’est-ce qu’une œuvre, si elle est aspirée par des algorithmes et remixée sans fin ? Les écrivains craignent de voir leur style et leurs idées réutilisés par des IA capables de publier des romans en un claquement de doigts. On peut se retrouver face à un tsunami de contenu généré, noyant la production humaine, et ce sans réelle rémunération pour les créateurs originaux.
Vers une armada de livres écrits par des IA ?
Depuis des années déjà, on assiste à un déferlement de fanfictions, d’articles et de textes générés ou co-générés par des modèles de langage. L’idée qu’une IA puisse pondre un roman à succès n’a plus rien de farfelu. D’ailleurs, les géants du divertissement (et du merchandising) l’ont bien compris : pourquoi payer des scénaristes ou des auteurs quand on peut générer à la chaîne des univers « clé en main » pour vendre des jouets, des films, des parcs à thème ?
Les auteurs de best-sellers craignent de perdre la main sur leur propre création. Et quand on sait que, pour certains écrivains, les revenus ne viennent même plus tant des livres, mais des adaptations ciné ou des produits dérivés… c’est un marché tentaculaire qui se retrouve menacé. Après tout, on pourrait imaginer qu’une IA conçoive tout un univers transmédia, du roman à la série télé en passant par la gamme de figurines, sans qu’aucun humain n’ait mis la plume au papier.
Comment sortir de cette zone grise ?
La question reste complexe. D’un côté, on ne peut ignorer que de nombreux lecteurs se tournent vers ces bibliothèques pirates parce qu’ils n’ont pas les moyens d’acheter tous les livres qu’ils désirent, ou parce qu’ils ont besoin d’accéder à des travaux de recherche bloqués derrière des paywalls. D’un autre côté, la piraterie porte préjudice aux auteurs et aux éditeurs, et l’ampleur du piratage par Meta soulève de sérieuses interrogations sur les méthodes des géants de la tech.
Faut-il renforcer les lois ? Imposer de nouveaux modèles de financement pour la culture et la recherche ? Mettre en place des bibliothèques numériques légales, financées par un système mutualisé ? Ou bien accepter que le savoir circule, même de façon illégale, parce que la connaissance doit être accessible ?
La grande question : pirates ou sauveurs du savoir ?
Pour beaucoup, la piraterie littéraire demeure un geste militant, un pied de nez à l’industrie de l’édition traditionnelle, trop gourmande. Pour d’autres, c’est un fléau qui prive les auteurs de juste rémunération et, à long terme, décourage la création. Au milieu de tout ça, Meta a créé un véritable électrochoc : voir un titan du numérique s’emparer de notre « héritage littéraire » pour le servir en pâture à ses IA, voilà qui fait réfléchir.
L’avenir est incertain. Les éditeurs continueront de lutter, les pirates de s’organiser, et les grandes entreprises tech de contourner la loi à grands coups de serveurs et d’adresses IP masquées. Lesquels sortiront vainqueurs de cette bataille ? Difficile à dire. Une chose est sûre : la révolution numérique n’a pas fini de secouer le monde du livre.
Et vous, qu’en pensez-vous ?
Est-ce qu’il faudrait complètement repenser la façon dont on rémunère les auteurs et protège les œuvres à l’ère des IA, ou bien est-il inévitable que le partage (légal ou non) règne en maître au nom de l’accès universel à la connaissance ?


